

Distributed Snapshots
Snapshot in distributed systems, i.e. on all the nodes in a cluster, is a challenging problem because nodes in a cluster don’t have a global clock.

Prerequisites:






Through my last series about Clocks & Version Vectors, the idea was to discuss problems establishing order/causality in a distributed system and ways to achieve the same. One problem in the real world, that needs both concepts is Distributed Snapshots!
Problem Statement
Point-in-Time Snapshots are critical for capturing the “consistent” state of systems, which can be restored in case of any loss of system state, making your system fault tolerant.
Taking a snapshot of one particular server is easy. You define a cut-off time and at that time, the state of the server(local state) at that exact time can be captured for the snapshot.
However, Snapshot in distributed systems, i.e. on all the nodes in a cluster, is a challenging problem because nodes in a cluster don’t have a common/global clock. Hence, it cannot be guaranteed that all the nodes in the cluster will capture their local state at the same “instant”.
In addition to the “local” state, there could be additional states associated with the distributed system, which are in transit i.e messages send from node 1 to node 2, but hasn’t arrived at node 2 yet.
The other constraint during snapshots is that it should not be a “stop the world” process and it should not alter the actual computations!!
In short, we need the distributed snapshot to create a “Consistent” snapshot of the global state of the distributed system, without impacting actual computations on that system.
The Precursor to Solution
The algorithm used for capturing distributed snapshots is the Chandy-Lamport algorithm(Yes! Leslie Lamport is also behind Lamport Clocks).
I’m writing the precursor to summarize the aspects of the paper which form the base for the actual solution. I’d highly recommend you read the paper.
Since we cannot establish a “global time”, we will communicate across nodes to help establish a common time. We can hence define our distributed system as a set of processes(nodes) and channels, which can in turn be represented using a directed graph.
Assumptions:
The components(both the processes and channels) are reliable and do not fail.
Channel can handle infinite messages(i.e is an unbounded buffer)
Delays experienced while sending messages on a channel are arbitrary but finite.
The snapshot algorithm does not interfere with the normal execution of the processes
Each process in the system records its local state and the state of its incoming channels
Model of the Distributed System:
An Event e can occur in process P and can change the state of P itself, and at most one channel in the system connected to P. Hence, an event e could be represented by the tuple <P, s, s`, c, M> where -
P — Process
s — state of P before sending the event
s`- state of P after sending the event
c — channel who’s state is altered by the event.
M — the message passed on the channel
A global state of the system is composed of the set of processes and channel states in the system. The initial global state is one where the processes are in their initial states, while the channels are empty since no messages have been exchanged.
Let’s take a simple example to understand how snapshots would work and where things could go wrong. We have two processes P & Q, with two uni-directional channels C1 & C2. A message/token M is present with P during the initial state and M can be passed around.

If you see the above system, only one instance of the message M is supposed to be present during any “global state” snapshot of the system. Let’s consider different scenarios -
The state of P is recorded when the message is with process P and the state of C1, C2 & Q are recorded at the same time. We’ll see only 1 instance of M in the global snapshot, which is consistent.
The state of C1, C2 & Q is recorded when the message is with P, while the state of P is recorded after it has sent the message to C1. In this case, the global snapshot will not see the message M, leading to an inconsistent snapshot.
The state of P is recorded when the message is with process P and the state of C1, C2 & Q are recorded after P has sent the message to C1. n this case, the global snapshot will see 2 occurrences of the message M, leading to an inconsistent snapshot.
From the above scenarios, you can see that the time at which the snapshot is taken across different components in the system is independent & can lead to inconsistencies in the snapshot!
Solution(Algorithm)
The solution relies on leveraging a Marker event, which is sent along the communication channels with actual messages. How we use the Marker to ensure we make consistent snapshot is the crux of the algorithm.
We can split the algorithm into different into multiple phases -
Initiation(Sending Marker)
Any process in our system can initiate the snapshot process. So let’s assume process Pi initiated the process.
On initiating the snapshot process, Pi records its own state(local state) and sends a marker message on all the channels(outward from Pi).
Pi then starts recording the messages from all the incoming channels.
2. Reception(Receiving Marker)
If a process Pj is receiving a marker on an incoming channel, we can have two scenarios. Let’s talk about the case where Pj receives its first Marker event.
Pj records its own state(local state)
It marks the incoming channel(let’s assume Cij) as empty.
Send the Marker event on all the outward channels from Pj.
Start recording the messages on all the incoming channels, except Cij.
In case Pj has already received a Marker event before -
Mark the state of the channel Cij to represent all the messages in the channel since the recording started.
3. Termination
The entire process terminates when -
i) All processes have received a Marker(this implies that all processes have recorded their local state).
ii) All the channels have had a Marker event processed through them.
I’d highly recommend you try and follow the algorithm for a simple 3-node system. Attached is a sample 3-node system & how it would work -
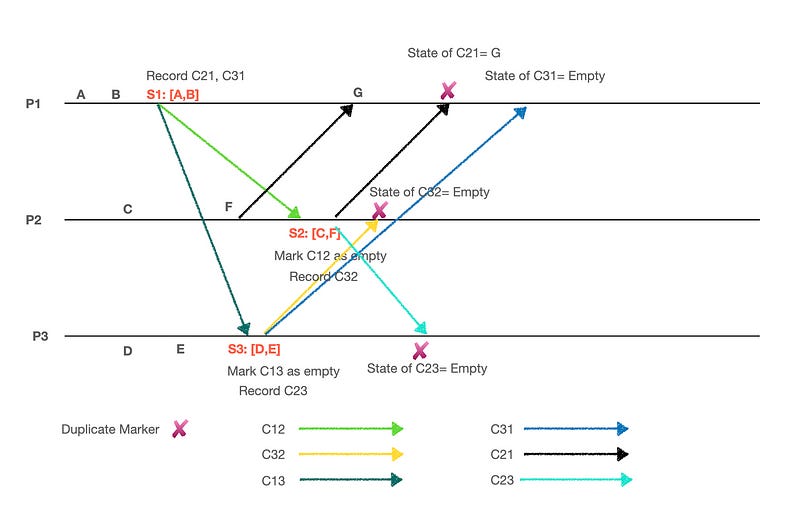
Let’s try & understand what’s happening in the above diagram. Consider it as a fully connected directed graph, where P1, P2 & P3 are the 3 nodes, and C12, C23, C13, C31, C32 &C21 are the 6 directed edges.
A, B, C, D & E are application events occurring in the different processes P1, P2 & P3.
P1 initiates the snapshot process. As part of that, it records its local state which is [A, B] & stores it in S1. It starts recording any messages on the inbound channels i.e. C21 & C31. It also sends a Marker event to all of its outbound channels i.e. C12 and C13.
P3 receives the Marker event from P1 & since this is the 1st Marker event P3 is getting, it will record its local state i.e. [D, E] and store it in S3. It marks the incoming channel C13 as empty(since it’s received the Marker from this channel already). It starts recording any messages on the inbound channels i.e. C23(C13 is marked empty & doesn’t need to be recorded anymore). P3 then broadcasts the Marker event on all of its outbound channels i.e. C31 and C32.
On P2, an application event F occurred and P2 send it to P1 through channel C21(channels can carry both Marker & application messages). P1 receives the event F and the received event is marked as G for better identification.
P2 receives the Marker event from P1 & since this is the 1st Marker event P2 is getting, it will record its local state i.e [C, F] and store it in S2. It marks the incoming channel C12 as empty(since it’s received the Marker from this channel already). It starts recording any messages on the inbound channels i.e. C32(C12 is marked empty & doesn’t need to be recorded anymore). P2 then broadcasts the Marker event on all of its outbound channels i.e. C21 and C23.
P2 then receives the Marker event from P3, & since it has already received a marker event from P1, it checks the state of channel C32 since it had started recording for application messages. No application events were received on C32 and hence it marks the state of C32 as empty and stops recording messages on this channel.
P3 then receives the Marker event from P2, & since it has already received a marker event from P1, it checks the state of channel C23 since it had started recording for application messages. No application events were received on C23 and hence it marks the state of C23 as empty and stops recording messages on this channel.
P1 then receives the Marker event from P2, & since it has a marker event, it checks the state of channel C21 since it had started recording for application messages. Application events G was received on C21 and hence it marks the state of C21 as G and stops recording messages on this channel.
P1 then receives the Marker event from P3, & since it has a marker event, it checks the state of channel C31 since it had started recording for application messages. No application events were received on C31 and hence it marks the state of C31 as empty and stops recording messages on this channel.
Since all the processes have received a Marker event and all the channels have propagated a Marker event, we can now consider the process to be terminated.
After the termination, the states recorded are -
S1: [A, B]
S2: [C, F]
S3: [D, E]
C21: [G]
C12, C13, C32, C31, C23: Empty
The combination of these states gives us a consistent global state. As you can see, the “global snapshot” is a combination of snapshots from processes as well as channels. Try out your own variation of snapshots to create a consistent global snapshot!
This brings us to the end of this article. We covered the challenges of capturing a distributed snapshot and then looked into the Chandy-Lamport Algorithm and how it works! Please post comments on any doubts you might have and will be happy to discuss them.