

Database Intermediate Series: SQL Isolation Levels Internals
MVCC plays a crucial role in enabling databases achieve isolation. Let's dive into Isolation using MVCC using practical examples.


In our last post, we talked about Database Isolation Levels and how different Isolation Levels allow us to balance the trade-offs between consistency, performance, and concurrency.
Now, let’s examine how databases can provide different isolation levels that allow us to operate with a high degree of concurrency and consider how these would be implemented internally. But, lets cover a core concept which will help us understand the internal implementation first -
MVCC(Multi-Version Concurrency Control)
MVCC is a concurrency control method that provides each user connected to the database with a "snapshot" of the database at a specific point in time.
MVCC operates by keeping multiple versions of data items within the database. These versions are created through transactions, which are attempting to modify data.
Advantages of MVCC:
Read operations do not block write operations, and vice versa. This means the database can handle a high volume of transactions without significant concurrency-related performance degradation. If you did not have MVCC, you would have to use locks to ensure read and write don't conflict.
Since different transactions operate on their versions, the overhead of managing locks is significantly reduced.
Now that you have a high-level idea about MVCC let’s proceed.
Isolation Levels
1. Read Uncommitted
Read Uncommitted requires the slightest implementation effort, as concurrent transactions can read uncommitted changes made by another transaction. So, all you need to implement the read uncommitted isolation level is to ensure all transactions can see the latest data state at any point, including uncommitted data from other transactions.
2. Read Committed
This isolation ensures that a transaction can only read changes committed by other transactions. So, how would this be implemented internally?
Each transaction sees the latest committed state of the records it’s operating on. The Read Committed isolation level is ensuring that while each transaction can maintain their own set of uncommitted records, which are invisible to other transactions, committed records will immediately be visible on next read across transactions.
3. Repeatable Reads
This isolation ensures that subsequent reads return the same data if a transaction reads a row, preventing non-repeatable reads.
Each transaction operates on its own “snapshot” of the records it’s operating on. The snapshot in Repeatable Read isolation level is taken at the beginning of the transaction and never refreshed during the lifetime of the transaction, i.e one transaction doesn’t even see the records committed by another transaction during its execution.
Implementation:
Below is a very basic implementation of how you could build a MVCC KV store that guarantees Read Committed Isolation Level.
Key Points:
Each write operation stores data in the transactions map, where key is transactionID. This allows us to have a separate changes list, per transaction, without interfering with the actual state of the data.
Only on commit, does the changes for the transactions get persisted into the Versioned Data store. The versioned data store holds the older versions as well, so the latest state of the data at any point is present in the last entry in the version store.
Since we only want to read committed data on every read, on each read operation, we read the Versioned Data Store for its latest version of the data to find the value for any key.

Below is a very basic implementation of how you could build a MVCC KV store that guarantees Repeatable Read Isolation Level.
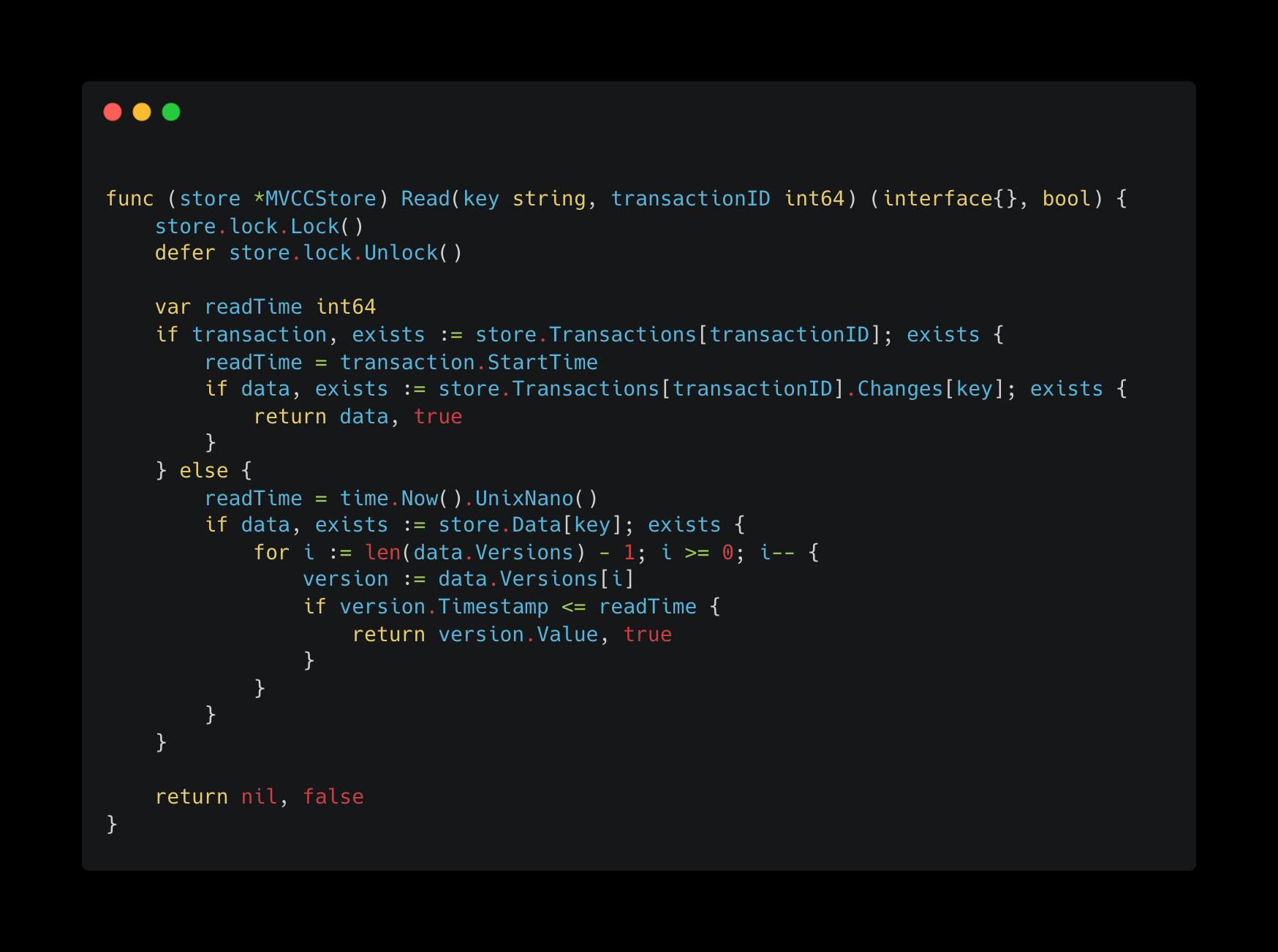
Key Points:
The only change we make to guarantee Repeatable Read Isolation Level is to our read function. With Repeatable Reads, we want to guarantee that the view of our data does not change with multiple read operations within our transactions.
To achieve this, instead of reading the committed data, if the transaction is active, we would re-read changes from the transaction’s change store. This allows us to see the data in the same state as we had at the beginning of our transaction.
The above is a very basic implementation to replicate MVCC and needs to handle edge cases before being productionized. This should only be used as a reference to understand MVCC concepts!
👉 Connect with me here: Pratik Pandey on LinkedIn
Github: https://github.com/pratikpandey21/database_series/tree/main/mvcc
Your database series with examples (in golang) is awesome. Have read your "isolation" post previously. Keep it coming!!!