

Database Basics Series: Understanding SQL Isolation Levels
Dive into how databases leverage Isolation Levels to provide you the flexibility to choose between high consistency and concurrency!

We are starting a new series on Databases, covering Basic, Intermediate, and Advanced concepts. This is the first article in the Database Basics Series!
ACID
Relational database systems that support transactions offer ACID guarantees for transactions. So, what do we mean when we say that a database is ACID compliant -
Atomicity: Guarantees that each transaction is treated as a single unit, either completed entirely or not. This property ensures that any changes made during the transaction are rolled back in case of failure, leaving the database state unchanged.
Consistency: Ensures that a transaction can only bring the database from one valid state to another, maintaining database invariants. This means that any transaction will leave the database in a consistent state according to the defined rules and constraints.
Isolation: Defines how transaction modifications affect data visibility to other transactions. The level of isolation determines the balance between concurrency and data consistency.
Durability: Once a transaction has been committed, it guarantees that the changes made are permanent, even in the case of a system failure. This is often achieved through logging and recovery mechanisms.
This article will focus on Isolation in ACID compliance and how databases support different Isolation Levels to balance the trade-offs between consistency, performance, and concurrency.
Isolation Levels
1. Read Uncommitted
This isolation level is the most permissive, allowing transactions to read changes made by other transactions before they are committed. This level provides the highest concurrency but risks reading uncommitted or "dirty" data, leading to inconsistencies.
What can go wrong if you choose Read Uncommitted?
Imagine if your favourite E-commerce company used read-uncommitted isolation level under the hood. Suppose a customer adds a product to a cart and hasn’t purchased it yet, but the item's availability from the inventory has been deducted. In that case, you see this updated inventory(i.e. product out of stock), even though the customer hasn’t updated the transaction. Now, if the customer cancels the transaction, the business suffers a loss, as no one purchased the product!
If you want to run analytics on your database, since your DB has uncommitted data, it’s never possible to get a consistent state!
2. Read Committed
This isolation ensures that a transaction can only read changes committed by other transactions. This prevents “dirty” reads like those in the Read Uncommitted Isolation Level but does not avoid non-repeatable reads, where a transaction could read the same row multiple times and receive different results if other transactions modify the data concurrently.
What can go wrong if you choose Read Committed?
Imagine if your favourite E-commerce company, which guarantees price-locking, used a read-committed isolation level under the hood. Suppose a customer adds a product to a cart but hasn’t purchased it yet. In the meantime, the seller updates the product's price and commits the transaction. When you add another product to your cart and refresh the cart, you’ll now see the updated product price breaching the price lock-in guarantee.
3. Repeatable Reads
This isolation ensures that subsequent reads return the same data if a transaction reads a row, preventing non-repeatable reads. However, this does not prevent other transactions from inserting new rows that match the query criteria. So, while you won't see changes to existing rows you've already queried, you can experience phantom reads because new rows that affect the result of re-executed queries can be added. Repeatable Reads is also the default isolation level in MYSQL databases.
P.S: Implementation of repeatable read isolation to allow phantom reads depends on the database provider implementation. Most implementations aim to prevent such reads but may do so with varying degrees of success.
What can go wrong if you choose Repeatable Reads?
Imagine if your favourite E-commerce company used a repeatable read isolation level under the hood. Suppose a customer adds a product to a cart but hasn’t purchased it yet. In the meantime, another customer adds the same product to the cart and proceeds with the purchase. When the first customer tries to make the purchase, you could get an error saying that the product is out of stock if the second customer purchased the last item.
4. Serializable
This is the strictest isolation level, ensuring complete isolation from other transactions. It makes a transaction appear to be executed serially rather than concurrently, eliminating dirty, non-repeatable, and phantom reads. This level provides the highest data consistency but can significantly impact performance and concurrency due to locking.
Isolation Levels in Action
To truly understand how isolation levels work, let’s experiment with different isolation levels and see how they behave in real-world concurrent systems. Below is a simple Golang application that simulates concurrent transactions to capture the behaviour for different isolation levels.
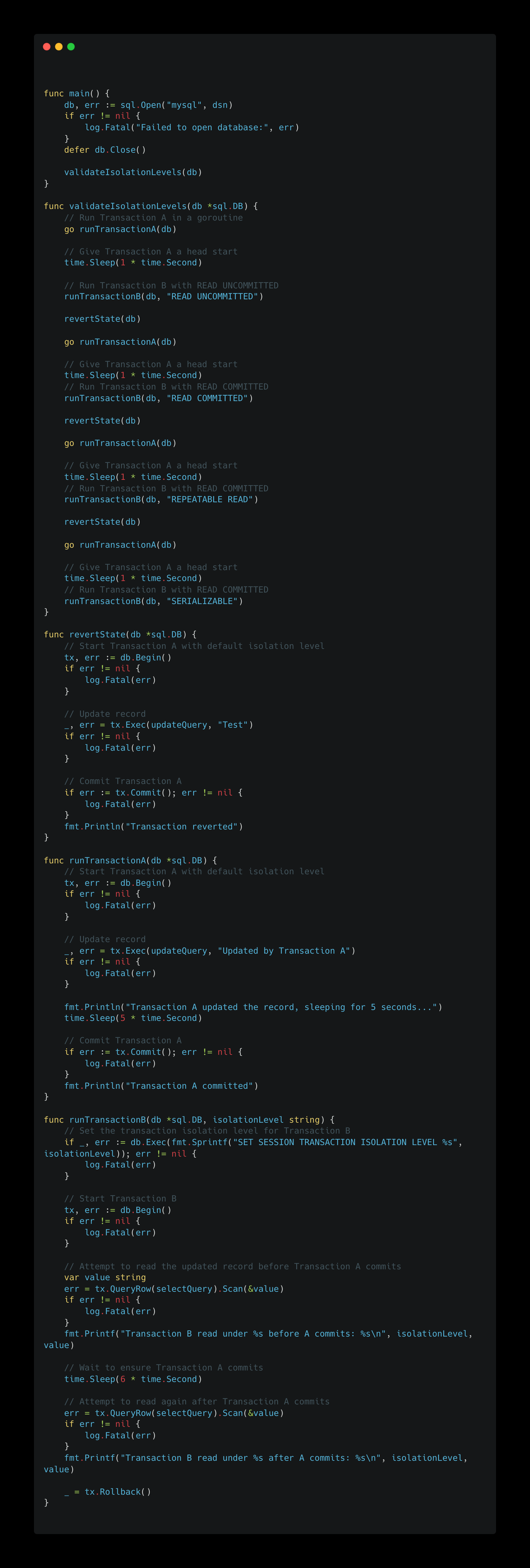
Understanding the Behaviour
1. Read Uncommitted
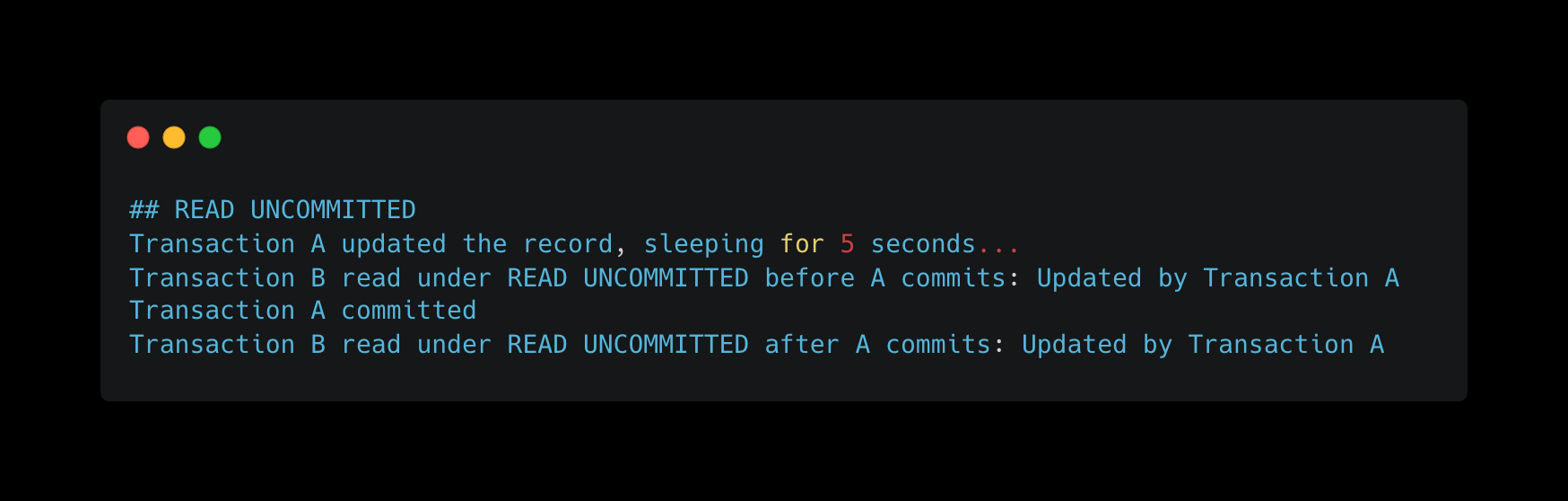
As you can see, Transaction B starts when Transaction A is in the middle of updating a value. Even though Transaction A hasn’t committed the value, Transaction B can see it, leading to Dirty Reads.
2. Read Committed

As you can see, Transaction B starts when Transaction A is in the middle of updating a value. When Transaction B reads the value the first time, it reads the committed value, Test. Transaction A commits, and when B re-queries the value, it gets the latest committed value, leading to Non-Repeatable reads.
3. Repeatable Reads

As you can see, Transaction B starts when Transaction A is in the middle of updating a value. When Transaction B reads the value the first time, it reads the committed value, Test. Transaction A commits, and when B re-queries the value, it cannot see the latest committed value, proving it has a completely isolated state and it follows Repeatable Reads.
4.
Serializable

As you can see, Transaction B isn’t even allowed to start while Transaction A is running at the Serializable isolation level. Even though they were running concurrently, they were executed sequentially.
Github: https://github.com/pratikpandey21/database_series
👉 Connect with me here: Pratik Pandey on LinkedIn
This is a fantastic explanation of isolation levels, especially with the relatable e-commerce examples! It really clarifies the potential consequences of each level.
In the real world, when choosing an isolation level, is there a specific decision-making process you recommend? Perhaps a framework to consider when prioritizing data consistency versus application concurrency?
I understood the isolation better with this article than in the database course I took in college, nice job!