

Build Distributed Systems: Cache to Distributed Cache
We implement a local cache with 2 implementations: One using Locks and the other without Locks. Dive in to understand the performance differences between the two implementations.

Welcome to the first article in our "Build Distributed Systems" series! We'll start our journey by building a local key-value cache in Go, complete with pluggable eviction policies, TTL support, and comprehensive performance analysis. This foundation will serve as the building block for our distributed cache system in future articles.

Why Start with a Local Cache?
Before diving into the complexities of distributed systems, it's crucial to understand the fundamentals of caching. A well-designed local cache teaches us about:
Memory management and eviction strategies
Concurrency patterns for high-throughput scenarios
Interface design for extensibility
Performance trade-offs in different implementations
Cache Design Philosophy
Our cache implementation prioritises four key principles:
Performance
We achieve high performance through careful selection of data structures and optimised concurrent operations. We'll compare sync.Map for simple cases with RWMutex for fine-grained locking.
Reliability & Correctness
Thread-safety, proper eviction mechanisms, and persistence to prevent data loss or corruption in production environments.
Maintainability & Extensibility
Interface-based design allows easy addition of new cache implementations or eviction policies without impacting existing consumers.
Observability
Good observability & metrics help monitor cache health and performance, essential for production debugging.
We’ll be building towards these design principles in the series. Not all of them will be present/covered in this article but it will be covered going forward.
Implementation Comparison
We've built two distinct cache implementations to explore different concurrency approaches:
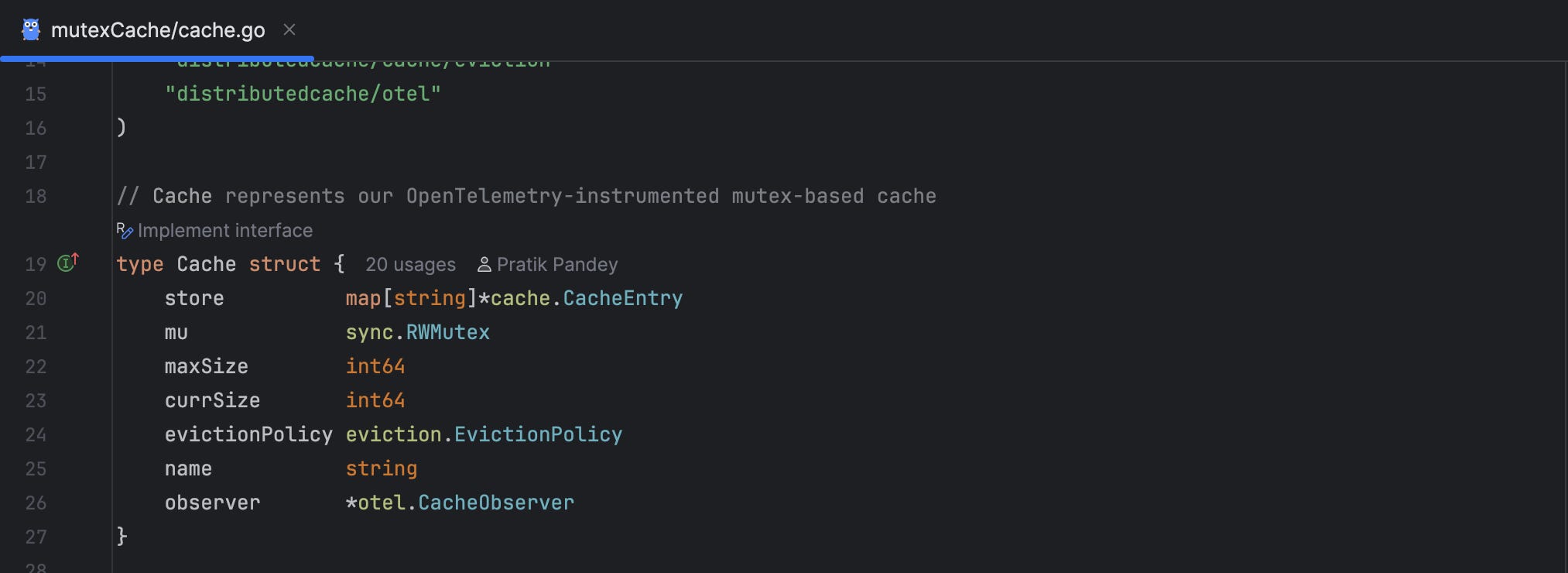
MutexCache: Cache using Locks
Design: Uses map[string]*CacheEntry protected by sync.RWMutex
Key Features:
Optimised for reads: RWMutex allows multiple concurrent readers
Direct map access: Efficient eviction without full iteration
Background cleanup: Go-routine removes expired entries every minute
LRU eviction: Efficient sorting of access times for eviction
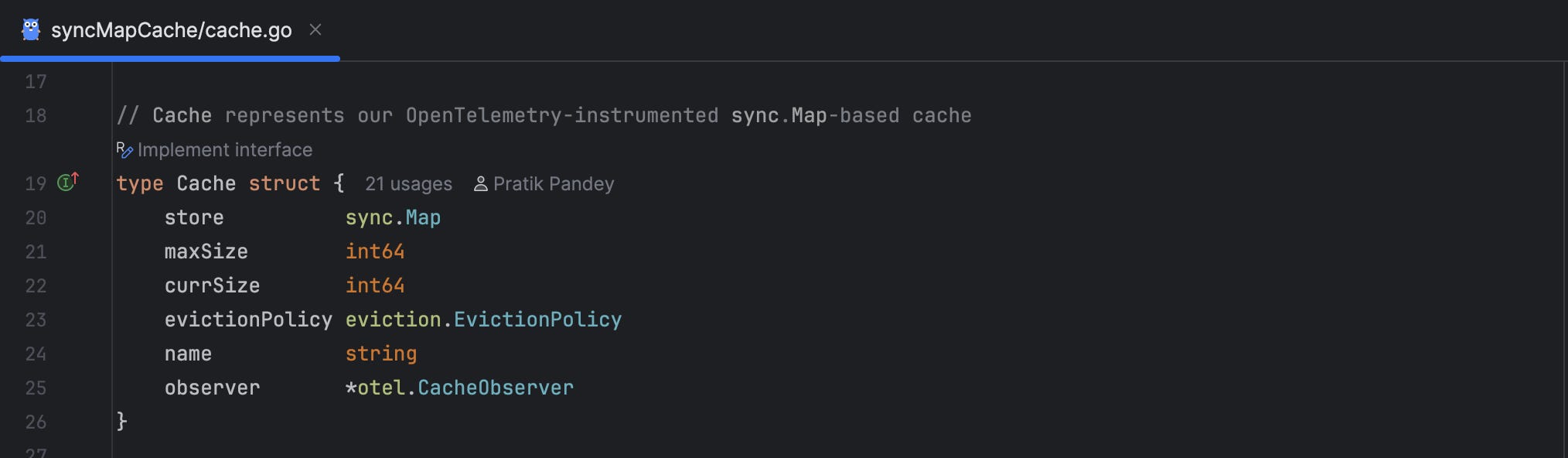
SyncMapCache: Lock-Free Cache
Design: Uses sync.Map with wrapper structs containing metadata
Key Features:
Lock-free reads: Excellent performance for read-heavy workloads
Atomic operations: Built-in thread safety from sync.Map
Pluggable eviction: Supports same eviction policies
Please do refer back to my last article on SyncMap to gain a deeper understanding into its internals.
Performance Analysis
SyncMap dominates in read-heavy scenarios

As you can see, SyncMap dominates read-heavy workload scenarios. But how? We’re using RWMutex, so it should be optimal right?
While RWMutex allows multiple concurrent readers, every read operation must acquire and release the RLock, which means there needs to be a synchronisation while acquiring and releasing the lock itself:
- c.mu.RLock() - synchronisation point
- c.mu.RUnlock() - synchronisation point
Under extreme contention (1000+ go-routines), these synchronisation points create CPU cache line bouncing and atomic counter updates within the RWMutex implementation.
Modern CPUs have multiple cores, each with their own cache hierarchy (L1, L2). Data is moved between main memory and the CPU cache in fixed-size blocks called cache lines, typically 64 bytes. To ensure that all cores have a consistent view of memory, a cache coherency protocol (like MESI) is used.
TheRWMutexcontains shared state (like counters tracking readers/writers) that gets modified frequently. When go-routines on different CPU cores try to access this shared state, the cache line containing that data gets "bounced" between CPU caches.
On the other hand, SyncMap uses atomic operations and doesn’t require any locks and hence read-heavy scenarios are more than 3x faster in our SyncMap implementation.
MutexCache performs better under eviction pressure


I urge you to try and go through the code to understand why this might happen. It’s relatively straight-forward to understand why syncMap implementation underperforms here.
This is not because of SyncMap’s internal implementation, but because SyncMap doesn't expose its internal structure for eviction operations. Hence to build eviction capabilities in our cache, we need to build our own implementation on top of syncMap.
Since we need to implement LRU eviction policy, we need to examine all entries to find the least recently used ones. Thus, to evict even a single entry, our cache must:
Allocate a temporary map for the entire cache
Iterate through every single entry using
Range()Perform type assertions from
interface{}for every entryCopy all entries into the temporary map
Run eviction logic on the temporary map
Use atomic operations to delete from the original sync.Map
For every eviction operation, SyncMapCache essentially duplicates the entire cache in memory. You can see this in effect in the benchmark stats, where the memory allocated for syncMap is nearly double compared to MutexCache implementation.
Conclusion
This brings us to the end of this article. Hopefully you enjoyed it and are excited for this series. The idea behind this article was to show you that there’s no one-size fits all solution, and more often than not, we need to evaluate trade-offs, which is what we tried to do.
While, we did see that SyncMap doesn’t perform well with evictions, it doesn’t equate to it performing badly with write-heavy workloads. It will depend on how frequently we’re evicting in those write heavy workloads.
Over our next articles, we’ll try to make this implementation more production-ready before we make it distributed.
👉 Connect with me here: Pratik Pandey on LinkedIn
💻 You can find the code on Github.
hey, this github link is giving 404
https://github.com/pratikpandey21/distributedcache
Nice benchmarking. Need to look at the code carefulky though.
I was building a similar concurrent application layer caching library in Go: https://github.com/Aki0x137/wind.
Looks like I should complete it after reading your article😅. I was originally inspired by a talk from a Dev at Reddit.
You might also want to look at decaying LFU caches. You can fine tune weights in it to decide how much it should behave like LFU and how much like LRU.