

Merkle Trees: The Data Structure for Verifiable State
A Merkle Tree is a binary tree of cryptographic hashes, constructed from the bottom up to efficiently verify data integrity.

In large scale data systems, trust is everything. But how do you verify that two massive datasets are identical without sending gigabytes of data across a network? How does a blockchain prove your transaction is included among millions of others without forcing you to download the entire chain?
This is one of the most fundamental challenges in distributed computing: how to achieve trust without transmitting your entire dataset. Traditional methods, which involve comparing entire datasets, are slow, expensive, and simply don't scale.

The Problem: Data Integrity at Scale
Let's imagine you're building a distributed storage system like Dropbox. You have several core requirements:
Redundancy: Files are replicated across many servers (nodes) to prevent data loss.
Consistency: Nodes must frequently verify that their copies of the files are identical.
Efficiency: Network bandwidth is a limited and expensive resource.
The naive approach—having one node send all its files to another for comparison—is an O(n) operation that becomes prohibitively expensive as the number of files (n) grows. This same challenge appears everywhere:
Blockchain networks need to prove a transaction is in a block.
Distributed databases must synchronize replicas efficiently.
Version control systems like Git need to compare repository states.
Certificate Transparency logs have to prove that a specific SSL certificate has been issued.
Merkle Trees: A Cryptographic Fingerprint of Your Data
A Merkle Tree is a binary tree of hashes. Its structure is built from the bottom up:
Leaf Nodes: Each leaf node stores a cryptographic hash of a single block of data (e.g., a transaction, a file, or part of a file).
Parent Nodes: Every non-leaf node stores a hash created by combining the hashes of its two children.
This process continues up the tree until only one hash remains: the Merkle Root. This single root hash is a unique and secure cryptographic fingerprint of the entire dataset. If even a single byte of data in any leaf node changes, the Merkle Root will change completely.
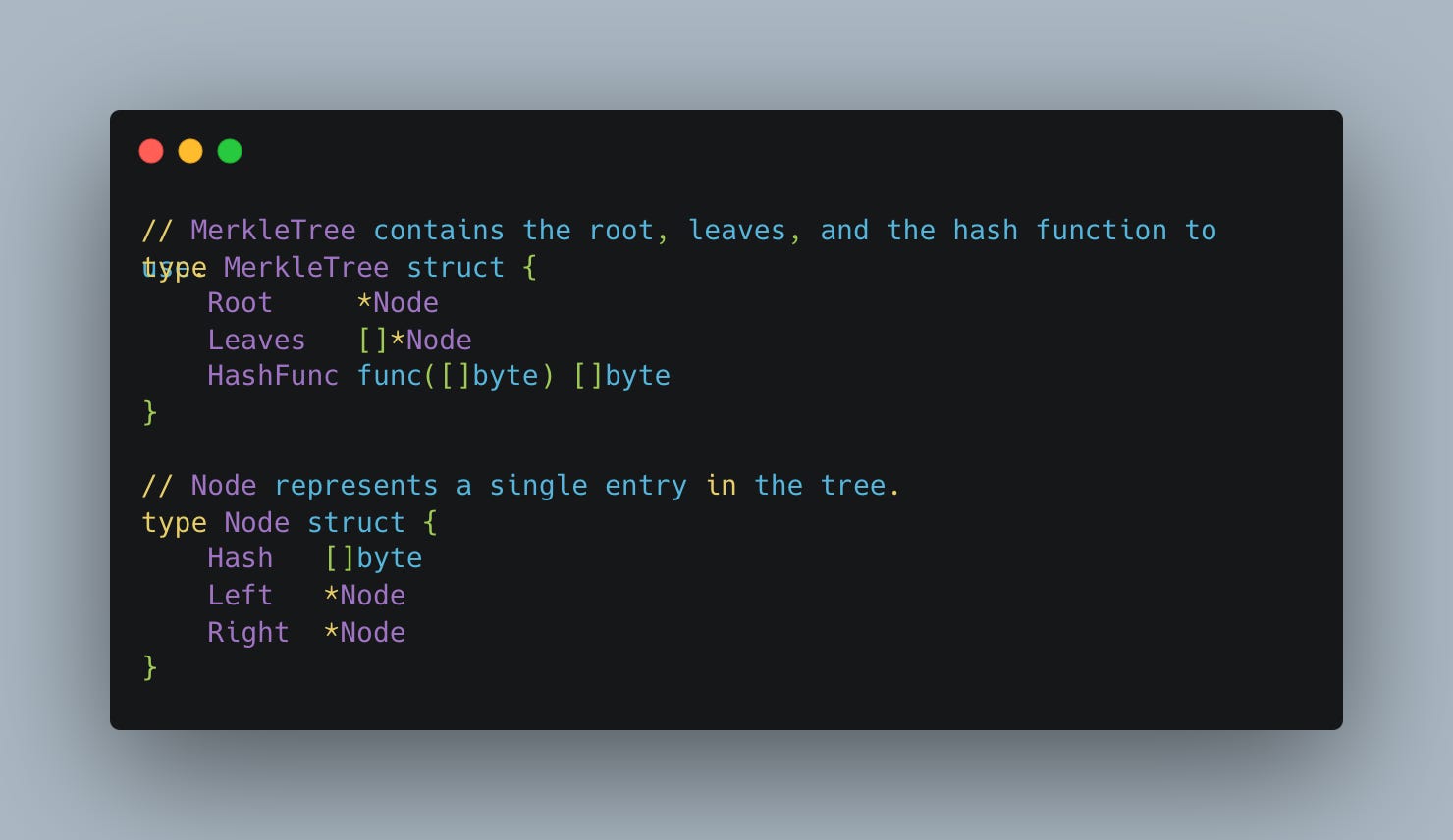
At a high level, the structure can be represented like this in Go:
The Magic: Proving Membership with Logarithmic Proofs
The true power of a Merkle Tree lies in its efficiency. To prove that a specific piece of data exists in the dataset, you don't need the entire dataset. You only need a tiny number of hashes.
This is called a Merkle Proof (or "audit path"). It consists of the sibling hashes along the path from the data's leaf node up to the root. To verify the proof, you just need the data's hash, the proof's sibling hashes, and the final Merkle Root.
Consider a dataset with 1 billion entries:
Traditional approach: Transmit all 1 billion entries for verification (potentially gigabytes of data).
Merkle Tree approach: Transmit only ~30 hashes to prove membership (log_2(10^9)).
This reduces the data required for verification from gigabytes to mere kilobytes—a staggering improvement of several orders of magnitude.
Real-World Implementations
Bitcoin: Bitcoin uses Merkle Trees to organise transactions in every block. A block with 2,000 transactions can prove any transaction's inclusion with just 11 hashes. This enables "light clients" (like mobile wallets) to verify transactions without downloading the entire multi-gigabyte blockchain.
Git: When you run
git fetch, Git uses Merkle Tree-like structures (Merkle DAGs) to determine exactly which objects (files, commits, etc.) need to be transferred. Instead of comparing every file, it compares root hashes and only traverses the branches that differ.Amazon DynamoDB & Apache Cassandra: These distributed databases use Merkle Trees for "anti-entropy" or replica synchronisation. Nodes can quickly identify inconsistent data partitions by comparing Merkle Roots, then "drill down" only into the divergent branches, minimising network traffic and computational overhead.
Limitations of Merkle Trees
High Overhead for Dynamic Data Merkle Trees are optimized for static or append-only datasets. Updating a single leaf requires recalculating all hashes on the path to the root—an O(log n) operation. In systems with frequent updates, this overhead can become a bottleneck.
Rebalancing Complexity For the best performance, a Merkle Tree should be balanced. As data is added or removed, maintaining this balance can be complex and add overhead. Unbalanced trees lead to longer proof paths and degraded performance.
In Summary
Logarithmic Proofs: Merkle Trees let you prove that a piece of data is part of a large set using a tiny amount of information (O(log N)).
Core Use Cases: They excel at verifying data integrity and synchronising data in distributed systems with static or append-only data.
Key Trade-Offs: They face challenges with datasets that change frequently, and they introduce storage and computational overhead.
Proven in Production: Real-world systems from Bitcoin and Ethereum to Git and Cassandra rely on Merkle Trees for efficiency and security.
This concludes the article introducing Merkle Trees. In the next edition, we’ll dive deeper into Merkle Trees with the help of a sample implementation in Golang!
👉 Connect with me here: Pratik Pandey on LinkedIn
Hey awesome content. I also wrote about Merkle Trees a while back: https://open.substack.com/pub/ahmazin/p/merkle-trees?r=1tezps&utm_medium=ios