



Replication Reconciliation: Architecture Pattern
Replication Reconciliation allows you to bring old cluster leaders to the same state as new leaders by reconciling changes from older generations.

Prerequisite:

In my last article, we talked about High Watermark. We were able to achieve a consistent view despite failures/crashes in our highly available system. But, there was an edge case, where the system was becoming inconsistent.
The edge case comes when the current leader gets a few records, writes them to its WAL and then crashes before the latest records were replicated to the followers. Now, a new leader is elected, which doesn’t have those records. Now, the WAL of the old leader & new leader are not in sync & this is where we have the consistency issue.
Before going into the solution, let me talk about something that would really help with the solution.
Generation/Epoch
Each time the leader election happens, a new generation id(auto-incremented) is attached to the new leader. So let’s assume, our cluster just started, and the leader for each partition gets allocated generation as 1. All records written to the WAL can also carry some metadata which can talk about the generation of the leader.
If the leader goes down and a new leader is elected after the leader election, the generation of the new leader will be 2, & all records written to the new leader will carry the metadata containing the new generation.
Back to the problem
Below is the current state, once the old leader comes back online. It will join back the cluster as a follower, as there is already a new leader.

As you can see from above, S1(server 1) has got offset 3 from generation 1, while all the other servers have got offset 2 as the last offset from generation 1. How do we fix this?
Replication Reconciliation
To resolve the above problem, we use the concept of Replication Reconciliation. Once the old leader(S1) comes back up, it will fire a FETCH LATEST request to the new leader.
However, along with its latest offset, it will also pass the latest generation to the new leader.
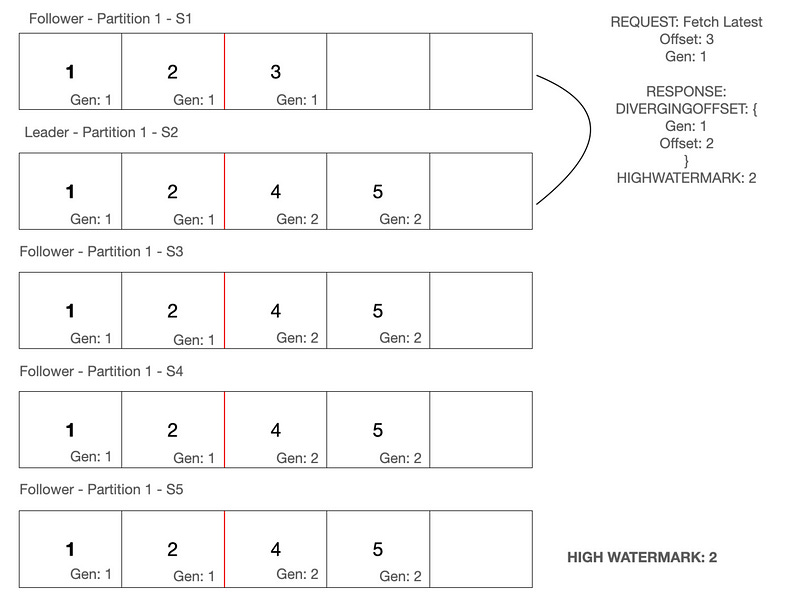
When the new leader(S2) receives the fetch latest request, it realizes that S1’s request does not match its local state. The highest offset S2 has with Generation 1, is 2. Hence, S2 responds back to S1, that there are diverging offsets in S1’s local state & it provides information on the latest offset available with its(S1’s) local state, for generation 1.
Post receiving the diverging offset response, S1 deletes all entries for generation 1 in its local state, after offset 2. So now, this will be the current state of the servers.
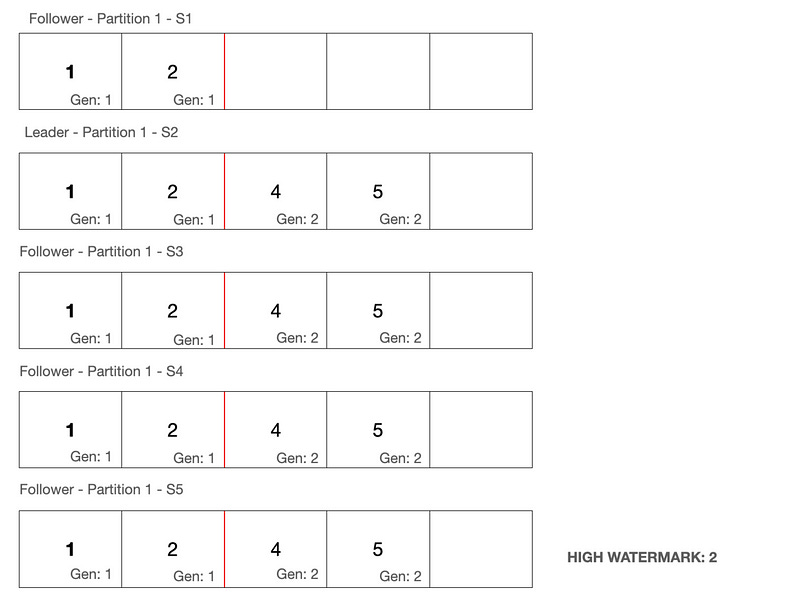
S1 after deleting the diverging records, will fire another fetch request to get the latest records.

This time, the new leader S2, finds no conflicts in its local log, vs the request from S1. It responds back with the latest records it has post offset 2, with a generation more than or equal to 1.

So, leveraging High Watermark along with Replication Reconciliation, allows us to give a consistent view to the end-users, in a highly distributed setup as well. Just to state the obvious, we are just creating a consistent view of the data store, the actual data across the different servers might still be inconsistent, but we never let the users see the inconsistent data.
Apache Kafka leverages Replication Reconciliation to ensure consistency of local logs/WAL across the leader and followers.
What about the data 3 in S1? Since after reconcialtion S1 cleared it so its lost, right?