

Consistency Model: Distributed Data Stores
A consistency model is a contract between a (distributed)system and the applications that run on it.

Prerequisite:

In my previous article, we talked about Consistency and Consistency Levels. We also discussed that playing around with Consistency Levels allows you to tune the Consistency requirements of your application & also impacts the Availability, Latency & Throughput of your application.
In this article, we’ll go a little deeper into Consistency & Consistency Levels & talk about Consistency Models, before looking into how consistency requirements for your application can be tuned based on Consistency Levels.
Consistency Model
A consistency model is a contract between a (distributed)system and the applications that run on it. This model is a set of guarantees made by the distributed system so that the client can have expected behaviour across read & write operations.
Strong Consistency Models
As we discussed in the previous article, Strong Consistency is achieved when all replica nodes are always in sync with each other.
There are multiple models within strong consistency itself! So we’ll go through some of them in detail in this article -
Linearizability
Linearizability is the strongest form of consistency. All operations are executed in a way as if executed on a single machine, despite the data being distributed across multiple replicas.
What does the above mean?
Let’s take an example. For a better understanding of Linearizability, think of everything from a client’s(Client interacting with the server/cluster) perspective.
We wrote a KV pair on my data store, at time T1 & the operation was completed at time T2.
We can now have 2 scenarios. A client can send a read request for the same key before time T2 —

Or, the client can send a read request for the same key after the time T2.

In case, the client operation to read a value started after(wall clock time) the write operation is finished, the read operation & any subsequent read operations should be able to read the write. That’s the concept of Linearizability.
If the client operation to read the value happened before the write operation finished, there’s no guarantee whether the read operation will be able to see the latest write.
Now, let’s extend the same to 2 clients.
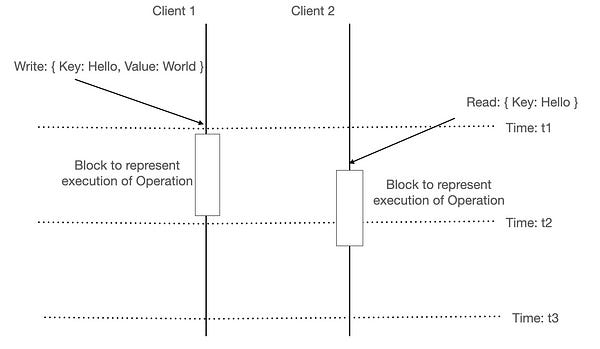

Even in this scenario, if Client 2’s read operation starts post Client 1’s write operation completes(wall clock time), it's guaranteed to see the latest write.
One question you might have is, Why look at it from a Client’s perspective?
Looking at it from a client’s perspective allows you to abstract away the complexities of your application & just makes you focus on how your application should behave if it supports the Linearizability guarantee. Your application might be deployed on a single server/on a cluster & the linearizability guarantees still hold.
Linearizability guarantees that for any successful write to the system, any consequent reads(in wall clock time) should be able to see the latest state of the data, hence ensuring Strong Consistency. This also implies that all replicas in a distributed system must have the same total ordering i.e. each replica can be expressed as a series of write operations on the data store & the order of operations must match.
Just to add, in the case of two concurrent writes, it does not matter the order in which the writes are executed, linearizability should ensure that the order in which the concurrent writes are executed is common across all the replicas.
Causal Consistency
Causal consistency is a relaxed/weakened form of the Strong Consistency Model defined by Linearizability. Causal consistency preserves the order of causally related operations. Causally related operations can be captured by defining the happens-before relationship. Let's take an example -
If A happens before B, then A must be executed before B on all replicas. However, for concurrent operations, we cannot define happens-before relationships & hence we might not see concurrent operations in sync across replicas.
Let me explain the difference between total ordering & causal ordering -
Total Ordering(Across All Replicas) — A < B < C <D < E < F
Causal Order(Replica 1) — A, B < C < D < E, F
Causal Order(Replica 2) — B, A < C < D < E, F
In the above example, A-F is a set of operations, where A&B are concurrently executed and E&F are concurrently executed. C however happens after A&B, D happens after C and so on.
In total ordering, we could define an ordering between all events on the replicas, while in causal ordering, concurrently executed operations are not ordered the same across replicas, while causally related operations are.
Causal consistency implies that reads are latest only with respect to the writes that they are causally dependent on. Moreover, only causally-related writes are ordered by all replicas in the same way. Concurrent writes can be committed in different orders.
PRAM Consistency/FIFO Consistency
PRAM Consistency is a more relaxed model compared to Causal Consistency. In PRAM Consistency, all write operations from a single process are always maintained in the order they were executed. However, there is no guarantee on the order in which different processes see writes from different sources.

If you see above, the write of x = 1 & x = 1.5 are causally related, however, since PRAM is a weaker consistency model compared to Causal, the sequence of operation on replicas where the operation wasn’t executed cannot be guaranteed for operations across processes.